
Sommario:
- Con il crescente sviluppo tecnologico e la condivisione sempre più di frequente di informazioni personali su internet, come sta cambiando il concetto di privacy? Fin dove può essere tutelata? Quali sono le conseguenze reali nella vita causate dalla violazione della privacy sul web? Possiamo fare qualcosa per proteggerci?
- Partiamo con un po’ di “teoria”
- Ma quali sono i dati che diffondiamo?
- I cookie, piccole “spie” onnipresenti
- Ma quali possono essere le conseguenze più pericolose della raccolta dei dati?
- Il caso Cambridge Analytica e come i dati possono arrivare ad influenzare i nostri pensieri
- Come possiamo proteggere la nostra privacy, a partire dal browser
- Le collaborazioni (più o meno recenti) tra governi e big tech
- Conclusioni e un occhio al futuro
Con il crescente sviluppo tecnologico e la condivisione sempre più di frequente di informazioni personali su internet, come sta cambiando il concetto di privacy? Fin dove può essere tutelata? Quali sono le conseguenze reali nella vita causate dalla violazione della privacy sul web? Possiamo fare qualcosa per proteggerci?
Partiamo con un po’ di “teoria”
La privacy è definita dall’enciclopedia Treccani come “La vita personale, privata, dell’individuo o della famiglia […] costituisce un diritto e va perciò rispettata e tutelata”.
Tra le primissime definizioni c’è quella data da Samuel Warren e Louis Brandeis . Nel 1890 affermarono con forza su ”L’Harvard Law Review” il loro “right to be left alone”, cioè il diritto ad essere lasciati soli. Infatti proprio in quel periodo si era diffusa la pratica di fare foto a personaggi popolari alle feste private e di divulgarle poi su giornali locali di gossip. Dalla loro richiesta di essere tutelati da questo fenomeno nacque il primo concetto di privacy.

Oggi quando si parla di privacy ci si riferisce principalmente alla tutela ed al controllo dei dati personali. L’ Art. 4, co. 1, Dlgs. n. 196/2003 li definisce come “qualunque informazione relativa ad una persona fisica, identificata o identificabile, anche indirettamente, mediante riferimento a qualsiasi altra informazione, compreso un numero di identificazione personale”.
Coerentemente con questa definizione quindi, si intende “violazione della privacy” un trattamento illecito dei dati personali che può portare ad identificare una persona una volta conosciuti i suoi dati. È considerata violazione anche la mancata adozione di misure di sicurezza necessarie a proteggere i dati, oppure la trasgressione dei provvedimenti previsti dal Garante della Privacy.
Chi è il Garante della privacy? E cosa fa per proteggere le nostre informazioni quando vengono diffuse?
Il Garante è una autorità amministrativa istituita nel 1996, che si occupa di tutelare i diritti di riservatezza dei cittadini. Questo avviene tramite controlli su come vengono trattati i dati da parte di diversi enti o grazie all’adozione e al suggerimento di nuove norme al legislatore. Inoltre esamina i reclami presentati nel caso di violazione di privacy e applica i provvedimenti previsti quando è necessario. Il garante fa spesso riferimento al GDPR – General Data Protection Regulation– regolamento emanato nel 2016 dall’Unione Europea che mira a regolare la tutela della privacy. In particolare cerca di armonizzare la regolamentazione in materia di protezione dei dati personali tra gli stati EU e a tutelare maggiormente la privacy dei cittadini con regole stringenti.
Cosa succede se c’è una effettiva violazione dei dati?
Nel caso in cui ci sia un Data Breach, ossia una violazione delle informazioni, sia il garante che il proprietario dei dati devono essere avvertiti dal titolare dei dati (cioè colui che ne è legalmente responsabile). Quest’ultimo deve immediatamente allertare anche l’autorità competente nel caso di rischio concreto per il proprietario dei dati.
Ovviamente ci sono delle conseguenze legali nel caso si trovi il colpevole. Le ripercussioni per chi accede abusivamente a dispositivi o account di altri, diffonde informazioni, spia il computer altrui o diffonde informazioni variano. Possono arrivare ad una multa oltre 1500€ e la reclusione fino a 3 anni. Per il risarcimento poi, si rischia di dover arrivare a pagare fino a 60 mila € all’offeso.
Nel caso si voglia approfondire, si possono trovare moltissime notizie utili alla pagina del Garante. Si trovano informazioni sia per utenti che vogliono tutelare maggiormente i propri dati, sia per titolari del trattamento.
Ma quali sono i dati che diffondiamo?
Facendo un passo indietro viene naturale chiedersi quali siano i dati che cediamo ai vari siti, sia consapevolmente che, molto più spesso, inconsapevolmente e fin dove si può arrivare con tutte queste informazioni.

Praticamente tutti hanno già fornito nome, cognome, mail e data di nascita semplicemente per farsi un account social. Oltre a sapere ciò, i social network memorizzano coscienziosamente qualsiasi ricerca facciamo, quali video vediamo o che profili consultiamo. In questo modo è facile rielaborare le informazioni e creare un profilo virtuale che arriva a conoscere con una discreta precisione i nostri gusti.
Per esempio, cosa sa Google?
Contando che in Italia oltre il 94% delle persone usa Google come motore di ricerca da PC e il quasi 99% da mobile, si può affermare con sicurezza che Google conosca moltissimo di noi. Per esempio registra le nostre posizioni e i nostri spostamenti quando usiamo Google Maps. Potete trovare tutti i giri che avete fatto recentemente nella timeline di Maps.
Nella cronologia inoltre vengono salvate tutte le ricerche che facciamo e i link che visitiamo quando andiamo su Google Search. Nella pagina “Le mie attività” di Google si possono trovare, oltre alle ricerche, anche le attività su app collegate al nostro account e i video che guardiamo su Youtube (dato che si può usare l’account di Google per accedervi).
Infine Google conosce anche gli appuntamenti che pianifichiamo, da quando registriamo tutto su Google Calendar. Con Calendar si possono inserire data, luogo, ora e partecipanti all’evento. Nel caso qualcuno riuscisse ad entrare nei nostri profili, saprebbe esattamente dove trovarci, quando e con chi.
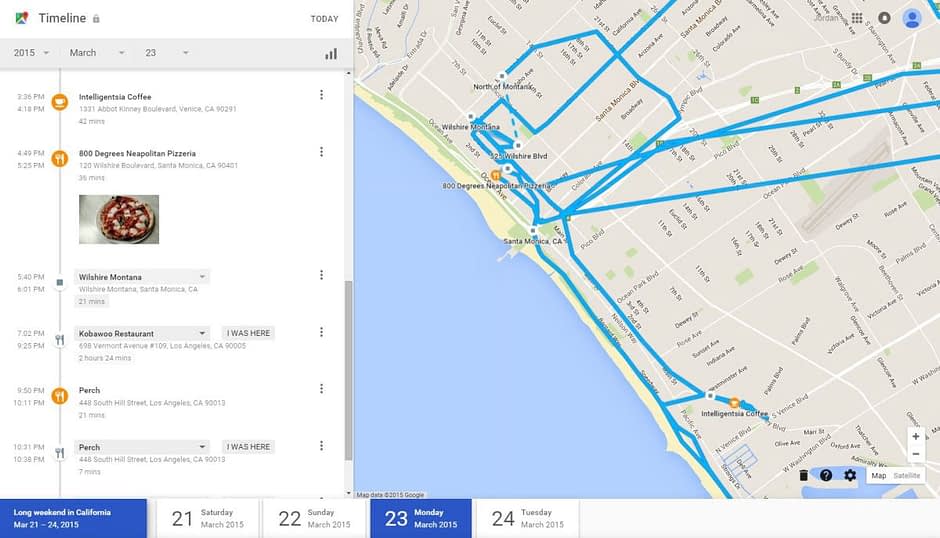
Nonostante tutte queste funzionalità ci semplifichino quotidianamente la vita, lo stretto collegamento tra tutte le app di Google ha già iniziato a dare i primi problemi nel 2019. Un bug dell’integrazione tra Gmail e Calendar infatti, ha messo in pericolo oltre un miliardo di utenti. Il rischio a cui si era esposti era il potenziale furto di identità. Attraverso mail di spam venivano aggiunti automaticamente eventi ai calendari degli utenti e a questo seguiva l’invio di notifiche che portavano l’utilizzatore ad essere indirizzato ad una pagina pericolosa. Qui si richiedevano informazioni personali tra cui numeri di carta di credito, identità, telefono e indirizzo.
Il caso Alexa
Google comunque non è l’unica compagnia ad avere quantitativi ingenti di dati su di noi.
Con la mobilità ridotta causata dalle restrizioni per la pandemia, nell’ultimo anno Amazon ha visto crescere esponenzialmente consumi e consumatori .
Esattamente come Google, anche Amazon raccoglie dai suoi utenti qualsiasi tipo di dato riesca ad estrapolare. Dai classici nome, indirizzo e ricerche effettuate, ai più delicati dati di pagamento e credenziali del Wi-Fi, la compagnia di Bezos conserva tutto.
Tra i servizi offerti da Amazon, quella che porta alla più pericolosa violazione della privacy è Alexa, l’assistente vocale. Si sentono continuamente storie inquietanti di Alexa. Spesso risponde anche se non interpellata, o suggerisce di comprare prodotti mai cercati, di cui però si era discusso in precedenza davanti all’assistente vocale. Questi sono segni evidenti che nonostante già memorizzi tutte le richieste che gli vengano fatte, ascolta (e probabilmente registra) costantemente tutte le conversazioni. Nel 2018 in Oregon, Alexa ha addirittura registrato l’intera conversazione di una famiglia per poi mandarla come messaggio ad un contatto per errore.
La sua sua ormai celebre tendenza al capire male la wake word, cioè la parola usata per attivarla, la porta spesso a parlare e a rispondersi da sola a suoni che interpreta male.
Oltre a questo, la sua capacità di sentire suoni anche molto deboli la porta ad essere pericolosa se messa per esempio vicino alla finestra. Qui può essere raggiunta da chiamate esterne. Nel caso in cui Alexa sia collegata alla macchina potrebbe accenderla da remoto, oppure alzare e abbassare le tapparelle e permettere a intrusi di accedere a casa vostra. Se non si sono disattivate le impostazioni di acquisto vocale invece, potreste facilmente trovarvi la casa piena di pacchi e il portafoglio svuotato per banali errori di comprensione di Alexa.
Inoltre, come provato dai ricercatori dell’Università delle comunicazioni elettroniche di Tokyo, l’assistente vocale può essere attivato da comandi mandati tramite laser dalla distanza di 110m.
Forse è arrivato il momento di ripensare a dove posizioniamo Alexa e cosa le chiediamo.
Vi siete mai chiesti perché, dopo aver cercato un alloggio su Airbnb o una particolare tuta su Amazon, nei giorni successivi i siti che consultate presentano quasi esclusivamente pubblicità su quello?
È colpa dei cookie.
No, non parliamo di biscotti.
I cookie nascono praticamente con internet. Sono dei pacchetti di dati che vengono memorizzati sul computer dell’utente e inizialmente servivano per controllare se l’utente avesse già visitato la pagina. Con il passare del tempo i dati sono diventando il nuovo petrolio e oggi i cookie si usano per raccogliere tutte le richieste e i movimenti che facciamo su un sito.
Da un lato i cookie sono molto utili. Ci permettono ad esempio di evitare di autenticarci ogni volta che entriamo sui social, tengono traccia del contenuto del carrello nell’attesa che decidiamo se procedere effettivamente con l’acquisto o salvano la lingua che abbiamo impostato per un sito specifico.
Dall’altra parte però “sanno” chi siamo, cosa ci piace e quello che abbiamo consultato su internet. Tutte queste informazioni sono spessissimo vendute, inviate e scambiate nell’industria della pubblicità digitale, l’advertising , finendo ad aziende anche lontanissime da noi. Ecco perché anche quando andiamo su Facebook compare la pubblicità dello stesso identico bungalow che abbiamo cercato dieci giorni prima su Booking.
Tra quelli che si sentono più spesso nominare, i cookie di terze parti sono quelli più insidiosi e pericolosi. Provengono da siti diversi da quelli che stiamo consultando, dato che sono contenuti in elementi come i video e le immagini che sono ospitati nella pagina. Sono creati apposta per profilare gli utenti e mostrare pubblicità in linea con i nostri interessi. Sono anche quelli che girano di più su internet, scambiati continuamente tra moltissime società.
Ma quali possono essere le conseguenze più pericolose della raccolta dei dati?
Innanzitutto, a causa della quantità colossale di dati che vengono raccolti sta diventando sempre più difficile proteggerli tutti. Solo nei primi sei mesi del 2019 4.1 miliardi di documenti sono stati esposti a causa di data breach.
Inoltre con la continua compravendita di dati e cookie tra le diverse aziende e la nostra tendenza a salvare le password per non doverle digitare ogni volta, ci esponiamo al rischio che i nostri profili social, email, e cose ben più gravi come app della banca vengano hackerati. In questo caso sarebbe semplicissimo trasferire soldi o fare acquisti su internet con la carta di altri.
Conoscendo così tanti dati delle persone non è difficile sostituircisi o indovinare password ed entrare nei profili online altrui. Arrivati a questo punti ci vuole poco a modificare dati di lavoro, cancellare file dal Dropbox dell’ufficio, rubare segreti professionali o addirittura rendere inservibile il computer. Questo succede spesso quando si è vittima di ricatti online a cui non si intende piegarsi.
Se invece i dati finissero nelle mani di compagnie assicurative, è quasi certo che gli algoritmi di oggi saprebbero profilarvi molto bene. Sarebbe facile arrivare a prevedere con una percentuale di sicurezza parecchio alta se siete a rischio di avere un incidente in auto (avendone già avuto uno, ma anche se non l’avete avuto). Saprebbero anche se siete soggetti a problemi di salute senza che voi gli abbiate dato alcuna informazione a riguardo. L’ovvia conseguenza è che le assicurazioni che vi proporranno avranno prezzi stratosferici.
Nel 2009 per di più, quando ancora i dati non erano onnipresenti (o almeno non ai livelli di oggi), ad un signore americano la banca ha imposto un massimale molto basso sulla carta di credito, solo perché aveva comprato nello stesso negozio in cui facevano acquisti persone famose per non ripagare sempre i propri debiti con le carte. Il signore in questione però pagava regolarmente.
Nel caso di aziende invece, l’hackeraggio può portare alla perdita di informazioni importanti che può causare uno svantaggio competitivo se i dati vengono poi diffusi. Se invece i dati rubati sono dei clienti, è possibile incorrere in conseguenze legali.
Il CelebGate
Una storia dai meccanismi simili a quella di Google Calendar del 2019 è successa tra il novembre del 2012 e il settembre del 2014 negli Stati Uniti. Ryan Collins, americano di 36 anni diede vita al CelebGate. Lo scandalo vide le immagini private di oltre 500 donne dello spettacolo statunitense rubate dai loro account iCloud e poi divulgate in rete.
Quello che Ryan Collins mise in atto fu una complicata rete di raggiri attraverso il phishing. Il phishing è un tipo di truffa con cui si cerca di rubare dati personali, finanziari e codici di accesso di account privati. I truffatori fingono di essere società affidabili, con cui si era magari già in contatto. Il phishing si realizza per lo più con l’invio di mail in cui la grafica simula con molta precisione quella della mail di una società reale. Dopo di che si chiede al destinatario di inserire i propri dati per poter risolvere un problema con l’account del cliente. I dati poi vengono salvati e spesso usati per sostituirsi alla persona vera nel fare acquisti, rubare dai conti o truffare altre persone.
Il caso del CelebGate, ha visto più precisamente l’utilizzo dello spear phishing. In questo caso il truffatore prima raccoglie diverse informazioni delle vittime su internet, poi le usa per riuscire a estorcere i dati di accesso. Collins oltre a raccogliere le informazioni ha usato una mail chiamata appleprivacysecurity. Mandata la finta mail che indicava problemi con l’account chiedeva e otteneva le informazioni di sicurezza per accedere agli iCloud delle celebs.
Un altro modo che si crede viene usato per accedere agli account è quello di indovinare le password, conosciuti molti dettagli personali delle vittime.

Nell’ottobre 2016 Collins è stato dichiarato colpevole per l’accesso non autorizzato ai computer delle vittime e condannato a 18 mesi di carcere.
Come si può contrastare il phishing
Il phishing però continua ad essere un problema. In Italia la crescita di casi è esponenziale. Nel solo 2019 un’indagine ha rilevato che poco più del 17% degli intervistati è in grado di riconoscere la truffa. Nel nostro paese il phishing è punito dall’art 640-ter del codice penale, e le pene arrivano a 3mila euro e una reclusione fino a 6 anni. Nonostante questo è importante imparare a riconoscerlo per difendersene senza dover arrivare in tribunale.
Uno dei segnali distintivi sono dei piccoli errori nei nomi delle aziende. In caso di dubbi, sempre meglio controllare il sito di cui non si è sicuri in uno dei tanti database che segnalano siti inaffidabili. Altre misure di sicurezza che sono state messe in atto sono l’implementazione nei browser di programmi di protezione che avvertono l’utente quando un sito è pericoloso, o anche il metodo dell’argomentare i login con password. Questa tecnica consiste nel far corrispondere ad ogni utente una immagine ben precisa durante l’iscrizione, che se assente o errata durante il tentativo di accesso, segnalerebbe un tentativo di phishing. Inoltre si consiglia sempre usare l’identificazione a due fattori in tutti gli account. Questo aiuta ad evitare che qualcuno possa entrare nei vostri account senza che voi ve ne accorgiate. Infine si raccomanda di controllare periodicamente quali sono i dispositivi collegati ai vostri account.
Altre informazioni si possono trovare sul sito della polizia postale.
Il caso Cambridge Analytica e come i dati possono arrivare ad influenzare i nostri pensieri
Nonostante ci siano quindi moltissimi modi per aggredirci sul web, moltissimi sono anche quelli per orientare e plasmare le idee di molti, presentando sia prodotti mirati, che contenuti culturali. Non è una novità che le aziende che trattano dati non si facciano scrupoli a mostrare agli utenti pubblicità in cui vengono presentati dati e notizie false per poter influenzare i loro acquisti o orientare il loro pensiero politico.
È proprio questo che è successo inizialmente nel 2016 e che ha portato negli Stati Uniti all’elezione di Donald Trump.
Si potrebbe pensare che l’elezione americana sia stata interamente conseguenze del libero voto dei cittadini. A partire dal 2018 però, grazie ad alcune inchieste condotte dal The Guardian e dal New York Times e la conseguente esplosione del caso Cambridge Analytica si è scoperto che non è andata proprio così.
La società
La Cambridge Analytica è una società britannica di consulenza nata nel 2013. A partire dal 2014 inizia a ricevere dati da un’applicazione di Facebook chiamata “This Is Your Digital Life”. Creata dal ricercatore Aleksandr Kogan, all’app si iscrissero circa 270mila persone. La trasmissione dei dati dall’applicazione di Facebook ad una società terza era (ed è) vietata. Nonostante l’azienda di Zukerberg fosse a conoscenza del passaggio dei dati da anni, ci sono volute le minacce di pubblicazioni dei due quotidiani per arrivare ad una sospensione dell’app di Kogan.

Con le impostazioni di privacy del tempo era possibile non solo raccogliere informazioni sull’utente, ma anche sulla sua rete di amici, il che ha aiutato Kogan a creare facilmente un bacino di dati che comprendeva quasi 87 milioni di contatti, come poi divulgato da Facebook.
I dati raccolti dall’applicazione, tra cui mi piace, commenti, posizioni e addirittura messaggi, erano poi rielaborati per costruire dei profili psicologici accuratissimi degli utenti. In seguito a questo sarebbero state proposte pubblicità in linea con gli interessi e le personalità degli utenti, grazie ad un algoritmi creato da Michal Kosinski. L’algoritmo era studiato per cercare di anticipare le risposte e i movimenti degli utenti. Kosinski ha affermato che ci vogliono 70 like di una persona per conoscerlo più di quanto lo facciano i suoi amici, 150 per saperne più dei genitori e 300 per saperne più del partner.
Le elezioni americane
Raccolti i dati dei circa 87 milioni di utenti, il lavoro della Cambridge Analytica è stato quello di mettere in atto campagne di marketing fortemente mirate che portavano gli utenti a vedere pubblicità a favore di Trump. Questo lo ha aiutato fortemente nella sua campagna elettorale, considerando anche che sono stati anche usati bot per screditare la Clinton che pubblicavano notizie false e post a sfavore della candidata democratica. Questo succedeva specialmente durante dibattiti televisivi in tempo reale.
Gli americani più colpiti da questa campagna sono stati gli swing voters, ossia quei cittadini non troppo sicuri delle proprie idee a cui è possibile far cambiare “fazione“. Con il sistema di microtargeting, sono riusciti ad individuare prima gli oppositori di Trump, e poi tra di loro quelli più disillusi e meno impegnati, quindi più carenti di una forte ideologia politica e più facilmente convertibili.
La regione più colpita da questo fenomeno è stata la California, con oltre 6.5 milioni di utenti fuorviati dalle campagne di Cambridge Analytica, seguita dal Texas con 5.6 milioni e dalla Florida con 4.3 milioni.
La Brexit
Un anno dopo l’entrata di Trump alla Casa Bianca, la Cambridge Analytica ha “dato aiuto e guida in una fase iniziale” nella campagna a favore della Brexit. L’ha affermato Andy Wigmore, direttore della comunicazione di Leave. Gli stretti collegamenti tra componenti della Casa Bianca ed esponenti del partito del leave hanno fatto insospettire il Financial Times. Il giornale ha tentato di trovare collegamenti in grado di dimostrare che anche questa votazione è stata controllata grazie agli strumenti di Facebook, arrivando a ben poco.
Tutto quello che si sa è che la campagna “Vote Leave” ha riciclato oltre 750 mila sterline. Con questi soldi si è scatenata un’ondata di disinformazione attraverso pubblicità false, azione poi dichiarata illegale.
L’Information Commissioner’s Office a inizio ottobre 2020 ha dichiarato la completa innocenza di Cambridge Analytica riguardo la Brexit. Restano comunque diverse ombre sul ruolo che ha avuto Facebook nella faccenda. Zuckerberg ha infatti declinato – e continua tuttora a farlo- tutte le richieste a spiegare l’accaduto nonostante le numerose richieste avanzate dal parlamento britannico.
Le conseguenze dello scandalo Cambridge Analytica
Le conseguenze di questi episodi non sono state poche. Non solo perché Cambridge Analytica ha dichiarato bancarotta a causa dello scandalo, ma anche perché si è iniziato a guardare con una maggiore consapevolezza il potere che possono avere dati e social combinati, nel mondo.
Nel 2019 Zuckerberg e la sua azienda sono stati costretti dalla Federal Trade Commission a pagare una multa di 5 miliardi di dollari e ad oggi Facebook ha modificato le sue privacy policies. Si sono assicurati che i dati raccolti dalle applicazioni non possano essere in alcun modo trasferite a terze parti per evitare un secondo caso Cambridge Analytica. Inoltre, i dati effettivi che le app possono effettivamente raccogliere sono diminuite drasticamente.
Ma c’è dell’altro.
Anche i governi hanno agito di conseguenza alla vicenda. La California, colpita duramente, ha fatto passare il California Consumer Privacy Act, nel giugno 2018. Il CCPA permette agli utenti di sapere quali dati vengono raccolti e con quali finalità (se per esempio vengono venduti e a chi). Inoltre stabilisce che il consumatore possa chiedere di cancellare i dati e controllare quelli di cui il sito è in possesso.
Come possiamo proteggere la nostra privacy, a partire dal browser
La valanga provocata da Cambridge Analytica però non si è ancora fermata. Anche Google ha deciso di bloccare nel giro di due anni l’uso di cookie di terze parti quando si accede a Chrome per evitare la diffusione di dati da parte di terzi. Gli sviluppatori di nuovi browser, a cui ci si può rivolgere per avere un maggiore livello di privacy, hanno invece iniziato a fare della protezione dei dati il proprio core business.
È il caso di Brave, un browser open source-lanciato 2016 e basato sul progetto di Chromium, web browser libero creato da Google. I punti di forza di Brave sono la protezione della privacy dei suoi utenti e il blocco parziale delle pubblicità.
Come fa Brave a tutelare l’utente?
Per tutelare la privacy dei suoi clienti Brave rende impossibile ricondurre il dispositivo da cui ci si connette all’utente in linea, non avendo alcun dato che lo possa rendere identificabile. Inoltre hanno implementato una funzione di rilevamento delle impronte digitali che impedisce ad aziende terze di controllare l’attività dell’utilizzatore. Le impronte digitali sono marcatori che vengono utilizzati per tracciare i movimenti dell’utente sul browser.
Oltre a ciò questo browser permette avere ancora più privacy usando TOR. The Onion Router è un software libero che permette di navigare su internet e comunicare contando sul più completo anonimato. Nella pratica TOR nasconde la cronologia di navigazione ai provider dei servizi internet (cioè l’azienda che vi permette di usare internet) e l’indirizzo IP al sito consultato, così da rendervi irrintracciabili.
Una particolarità da sottolineare è che Brave sta cercando di nascondere i pochi dati raccolti anche dai suoi stessi dipendenti. Per di più nei suoi termini d’uso si sottolinea che non si memorizzeranno, raccoglieranno o venderanno i dati in quanto proprietà privata. Questo significa che su questo browser non ci saranno frotte di annunci fastidiosi, ma solo contenuti in linea con i dati che rimangono sul computer. I dati quindi non gireranno più per le agenzie di marketing di tutto il mondo.
La mancanza di annunci per giunta, permette al browser di navigare più velocemente sul web, mantenendo comunque la possibilità di installare estensioni di Chrome.
E come guadagna Brave?
Il fatto di non avere annunci però non significa che i creatori di contenuti e proprietari di siti non guadagneranno più niente. Semplicemente guadagneranno in modo diverso. Brave infatti permette agli utenti di sostenere i propri siti preferiti pagandoli in criptovalute (BAT). Gli utenti stessi inoltre possono guadagnare dei BAT scegliendo di visualizzare annunci decisi da Brave stesso, invece di quelli standard.
Ecosia
I browser che ci tengono alla privacy e nel frattempo offrono “una ricompensa” non sono finiti. C’è infatti anche Ecosia, nato nel 2008 che oggi ha all’attivo 15 milioni di utenti. Oltre a proteggere la privacy rendendo anonime tutte le ricerche nell’arco di una settimana, Ecosia promette di piantare un albero ogni 45 ricerche per utente. Difatti l’80% dei ricavi è usato per finanziare la salvaguardia della foresta tropicale.

{kind=link}
Ecosia assicura anche che i dati non sono venduti a terzi e permette usare la funzione DNT che consente di non essere tracciati quando si fanno ricerche.
E oltre ai browser?
Nel futuro della privacy però non ci sono solamente i browser più consapevoli e attenti a proteggere i nostri dati, ma anche le applicazioni che usiamo. In questa direzione Apple ha compiuto il primo passo introducendo nel dicembre 2020 i privacy labels. Queste etichette indicheranno come vengono registrati i dati da ogni applicazione nell’App Store.
Le etichette possibili sono tre e contrassegneranno i “data used to track you” “data linked to you”, e “data not linked to you”.
I primi, cioè “i dati per tracciarti”, sono usati principalmente per andare a creare annunci mirati sulle ricerche e preferenze del cilente. I secondi invece, sono dati che possono essere ricollegati all’identità dell’utente nonostante non siano passati ad agenzie di advertising. Gli ultimi invece sono dati che non possono essere ricollegati all’identità dell’utente in nessun modo.
Tim Cook, l’amministratore delegato di Apple ha detto in un’intervista che l’azienda non è una “data company”. Non è quindi interessata a trattare e a trarre vantaggio dal trattamento dei dati dei suoi utilizzatori(nonostante qualcuno non sia proprio d’accordo). È per questo motivo che hanno introdotto le etichette, per poter permettere ai consumatori di fare una scelta più cosciente e ridurre i rischi di commercializzazione dei dati da parte delle applicazioni a terze parti.
Le collaborazioni (più o meno recenti) tra governi e big tech
Nonostante le affermazioni di Cook sulla tutela dei dati e il famoso rifiuto di creare un software per sbloccare il telefono di un terrorista nel 2016, è noto a molti che la Apple fornisca dati ai vari governi che ne fanno domanda. La compagnia della mela arriva a soddisfare fino al 90% delle richieste complessive, sia che queste siano coerentemente motivate, sia che queste non lo siano (specialmente se le richieste arrivano dall’FBI).
Ma Apple non è la sola a trattare i suoi big data con i governi. Google infatti ha creato un vero e proprio listino prezzi da sottoporre al governo per ogni richiesta di accedere ai suoi dati. Per una citazione si pagano 45$, mentre per un’intercettazione il costo sale a 60$. Un mandato di perquisizione invece, scuce al governo ben 245$.
Gli accordi per la lotta al Covid
Da quest’anno (2020, anno in cui si scrive) a causa della pandemia di Covid-19 sia la collaborazione tra i governi e le big tech che quella tra gli stessi giganti si è stretta ulteriormente. Per poter contenere l’epidemia i governi stanno facendo un uso sempre crescente di tecnologie che permettano di raccogliere, analizzare e condividere i dati con chi si trova in prima linea a combattere il virus. In particolare, i dati più richiesti sono quelli di geolocalizzazione per poter permettere un tracciamento efficace e dati biometrici come quelli di riconoscimento facciale. Ovviamente queste operazioni non sono esenti da rischi, perché una falla nel sistema permetterebbe di controllare spostamenti e dati di masse enormi di persone.
Nonostante i pericoli comunque governi come quello indiano hanno già iniziato da giugno collaborazioni con le big five. Con l’impiego di Facebook, Google e Whatsapp sono state promosse campagne informative di massa su rischi e prevenzione riguardo al Covid. Inoltre l’applicazione per il contact tracing sviluppata da una start-up indiana tiene i suoi dati sui server di Amazon.
A fine marzo invece il Regno Unito ha annunciato di aver avviato accordi con Google e Amazon per sviluppare una piattaforma di dati condivisa per contrastare la pandemia, e nel frattempo raccoglie dati anche da O2, compagnia di telecomunicazione sempre inglese per riuscire a contenere la diffusione del virus.
Hanno fatto lo stesso anche la Svizzera con Swisscom e l’ Austria con Telco A1, mentre il Belgio passa le informazioni che arrivano delle telecom ad agenzie terze. Lo scopo è sempre aiutare a monitorare la situazione della pandemia e rinforzare il distanziamento sociale.
Anche la Slovacchia ha provato ad usare metodi simili ma la corte ha dichiarato incostituzionale parte della legge che permetteva al governo di usare i dati presi dalle aziende di telecomunicazioni.
Una cooperazione anomala
Le collaborazioni però non finiscono qui, infatti Google e Apple hanno temporaneamente seppellito l’ascia di guerra per sviluppare una tecnologia che permetta di tracciare i contatti delle persone contagiate, al fine di ridurre la diffusione del virus ma stando attenti a evitare rischi per la privacy degli utenti.
Ad oggi sono circa una quarantina, tra cui circa 20 europei, i governi hanno fatto richiesta per poter utilizzare questa tecnologia. Secondo i regolamenti può essere usata per lo sviluppo di una sola applicazione per paese. In Italia è la ormai famosissima Immuni.
Le regole per utilizzare questo software sono molto strette, infatti il governo dovrà chiedere il consenso all’utente per poter raccogliere i dati, ma solo quelli necessari. Per di più l’app non potrà identificare gli utilizzatori ne targhettizzarli con le informazioni che si ottengono.
Le app per il tracciamento e i problemi di privacy
Questo però non calma la paura di molti legislatori che ci sia un abuso dei dati raccolti, e soprattutto che la raccolta dati non si fermi con la scomparsa del Covid.
In Lituania l’autorità di protezione dei dati ha sospeso l’utilizzo dell’app di contact tracing perché non soddisfaceva i criteri di tutela imposti dal GDPR. Nei Paesi Bassi e in Norvegia le applicazioni proposte non riuscivano ad incontrare i requisiti minimi di privacy e sicurezza, allungando i tempi di sviluppo e diminuendo quindi le possibilità di contenere il contagio. In Pakistan invece l’applicazione riusciva a localizzare perfettamente gli utenti e un bug permetteva agli hacker di accedere ai dati registrati, permettendo al governo e agli aggressori di sapere con precisione gli spostamenti degli utilizzatori.
Come sta andando invece in Cina?
Nonostante in occidente ci si interroghi e si provi a mantenere un certo rispetto sulla privacy dei cittadini, grazie soprattutto all’azione del GDPR, in oriente le cose non stanno proprio così.
La Cina, primo stato ad essere infettato dal virus, è anche stato il primo a liberarsene quasi del tutto. Un efficacissimo sistema di contact tracing e di isolamento sia delle persone contagiate che di quelle con cui i malati erano venuti in contatto, hanno permesso di tornare alla normalità in meno di un anno.

Ma quali sono veramente i fattori che hanno portato i contagi ad azzerarsi? E con quali conseguenze?
Sicuramente l’imposizione di misure rigidissime che lasciavano pochissima (se non nessuna) libertà ai cittadini per quasi due mesi ha dato una forte frenata alla diffusione del virus. Con la graduale riapertura però, la Cina ha messo in atto misure estreme per il tracciamento degli abitanti.
Le app di contact tracing
In accordo con le principali agenzie di telecomunicazioni, il governo ha accesso ai dati di tutti gli spostamenti degli utenti fino 15/30 giorni precedenti al controllo. Il tracciamento avviene grazie ad alcune applicazioni (ce ne sono diverse a livello locale fatte apposta per le diverse esigenze della regione) e per attivarle si richiedono nome, carta d’identità e scan facciale. Nonostante Pechino abbia dichiarato che i dati vengono usati solo per scopi relativi al contenimento del covid, non è stato chiarito da nessuna parte che sono stati presi provvedimenti per la tutela della privacy. Il governo infatti non solo non ha mai dato un intervallo di tempo dopo cui i dati raccolti vengano eliminati, ma non prevede nemmeno che debba essere dato un qualsiasi tipo di consenso per l’utilizzo dei dati.
Le applicazioni generalmente funzionano assegnando un colore tra il verde, il giallo e il rosso che viene deciso da un algoritmo che valuta stato di salute e movimenti recenti. Il colore verde permette ai cittadini di circolare liberamente, entrare in edifici pubblici, usare taxi e metropolitane dopo aver scannerizzato il Qr code prodotto dall’app. Se viene assegnato il giallo o il rosso scatta una quarantena rispettivamente di 7 e 14 giorni. È così che il governo cinese viene facilmente a sapere quali sono le abitudini dei cittadini o se si infrangono le regole (che porta ad un tempestivo intervento delle forze dell’ordine).
Chi l’ha vissuta
Peter Hessler, insegnante all’università di Sichuan, ha raccontato al New Yorker che riaperti i campus universitari, per potervi accedere bisognava essere scannerizzati da un sistema di riconoscimento facciale che riconosceva la persona, ne mostrava l’id e misurava la temperatura.
Inoltre gli studenti rimasti all’interno del campus non potevano uscirne ma potevano ordinare pacchi o delivery. Alcuni robot che giravano per l’università avevano il compito di consegnarli. Questi, dopo aver letto il qr code dello studente, rivelava il pacco all’interno del “serbatoio”. Un altro controllo che possono mettere in atto quindi, è quello sugli acquisti.
Conclusioni e un occhio al futuro
Finita la pandemia quindi, non è ben chiaro cosa succederà ai nostri dati, se rimarranno nei database o se verranno cancellati.
Certo è che nonostante i browser e i governi cerchino di tutelarci maggiormente ad oggi l’industria dei dati vale oltre 139 miliardi che si prospettano in continua crescita. Le informazioni quindi diventeranno uno strumento essenziale in qualsiasi campo. La cosa migliore da fare è educarsi e soprattutto prestare attenzione a tutto ciò che si comunica sul web perché con lo svilupparsi delle tecnologie si troveranno metodi sempre più innovativi per estorcere nuovi dati (in caso ci fosse ancora qualcosa che non abbiamo comunicato).
Secondo una riflessione del magistrato Buttarelli, contenuta nel volume “Privacy 2030: Una nuova visione per l’Europa” ci sarà un grosso incremento nell’uso di tecnologie come il riconoscimento facciale. Buttarelli sottolinea come si useranno sempre più spesso per reprimere intere popolazioni, giustificando l’azione come necessaria per la sicurezza. Malavika Jayaram invece sottolinea come, soprattutto in Asia, ci sarà una intrusione selettiva da parte di vari governi nella vita delle persone.
La privacy dunque è strettamente connessa alla democrazia. Servono regole più severe per la tutela di entrambe, ma possiamo arrivare ad averle solo con una precisa consapevolezza dell’importanza di tutti e due gli elementi.
Diritto.it. (2019). La violazione della privacy e le sanzioni previste dalla normativa comunitaria.
Diritto e finanza. Cos’è una violazione di dati personali. Alcuni esempi.
C.A.Garcia. (2017). Che cosa si rischia per violazione della privacy. La legge per tutti
Qui finanza. (2018). Quello che Google sa di te: come scoprire quali informazioni memorizza.
Simonetta B. (2019). Dati personali: così si cibano i padroni di Internet. Il Sole 24 Ore
La grande mela. Informativa sull’uso dei cookies.
Menietti E. (2018). Il caso Cambridge Analytica, spiegato bene. Il Post
Otlowski A. (2020). TWO YEARS LATER: CAMBRIDGE ANALYTICA AND ITS IMPACT ON DATA PRIVACY. HIPB2B
Goodin G. (2020). Brave browser-maker launches privacy-friendly news reader. Ars Technica
Hiller W. (2020). Is Big Data Dangerous? Career Foundry
Privacy International. (2020). Tracking the Global Response to COVID-19
Hessler P. (2020). How China Controlled the Coronavirus; New Yorker